flowchart TD
S1["① Prepare data\nconcentration data.frame\ndose data.frame"] --> S2
S2["② PKNCAconc()\ndefine conc column, time column,\ngrouping variables, route-specific args"] --> S3
S3["③ PKNCAdose()\ndefine dose, time, route\n(intravascular / extravascular)"] --> S4
S4["④ PKNCAdata()\ncombine conc + dose\nspecify intervals + imputation + units"] --> S5
S5["⑤ pk.nca()\nrun all calculations"] --> S6
S6["PKNCAresults\nsummary() / as.data.frame()"]
style S1 fill:#f0f4ff
style S6 fill:#e8f5e9
2 Workflow Overview
2.1 The Five-Step Workflow
Every PKNCA analysis follows the same five steps regardless of route or complexity.
2.2 Step-by-step: minimal example
Below is the complete workflow with the built-in Theoph dataset (oral theophylline, 12 subjects).
2.2.1 Step 1 — Prepare your data
PKNCA expects two separate data frames: one for concentrations and one for doses. Both must be in long format (one row per observation).
# Built-in oral theophylline dataset
head(Theoph)Grouped Data: conc ~ Time | Subject
Subject Wt Dose Time conc
1 1 79.6 4.02 0.00 0.74
2 1 79.6 4.02 0.25 2.84
3 1 79.6 4.02 0.57 6.57
4 1 79.6 4.02 1.12 10.50
5 1 79.6 4.02 2.02 9.66
6 1 79.6 4.02 3.82 8.58The columns are: Subject, Wt (weight, kg), Dose (mg/kg), Time (h), conc (mg/L).
# Concentration data: keep what we need
d_conc <- Theoph |>
select(Subject, Time, conc)
# Dose data: one row per subject (single dose at time 0)
d_dose <- Theoph |>
group_by(Subject) |>
summarise(Dose = Dose[1] * Wt[1], .groups = "drop") |> # convert mg/kg to mg
mutate(Time = 0)
head(d_dose)# A tibble: 6 × 3
Subject Dose Time
<ord> <dbl> <dbl>
1 6 320 0
2 7 320. 0
3 8 319. 0
4 11 320. 0
5 3 319. 0
6 2 319. 02.2.2 Step 2 — PKNCAconc
PKNCAconc tells PKNCA the structure of your concentration data via a formula: concentration ~ time | group1 / group2 / ...
o_conc <- PKNCAconc(d_conc, conc ~ Time | Subject)
print(o_conc)Formula for concentration:
conc ~ Time | Subject
Data are dense PK.
With 12 subjects defined in the 'Subject' column.
Nominal time column is not specified.
First 6 rows of concentration data:
Subject Time conc exclude volume duration
1 0.00 0.74 <NA> NA 0
1 0.25 2.84 <NA> NA 0
1 0.57 6.57 <NA> NA 0
1 1.12 10.50 <NA> NA 0
1 2.02 9.66 <NA> NA 0
1 3.82 8.58 <NA> NA 02.2.3 Step 3 — PKNCAdose
PKNCAdose describes the dosing. The route argument is critical — it determines which parameters are estimable.
o_dose <- PKNCAdose(d_dose, Dose ~ Time | Subject, route = "extravascular")
print(o_dose)Formula for dosing:
Dose ~ Time | Subject
Nominal time column is not specified.
First 6 rows of dosing data:
Subject Dose Time exclude route duration
6 320.000 0 <NA> extravascular 0
7 319.770 0 <NA> extravascular 0
8 319.365 0 <NA> extravascular 0
11 319.800 0 <NA> extravascular 0
3 319.365 0 <NA> extravascular 0
2 318.560 0 <NA> extravascular 02.2.4 Step 4 — PKNCAdata
PKNCAdata combines concentration and dose objects. If you don’t specify intervals, PKNCA automatically determines them from the dosing times.
o_data <- PKNCAdata(o_conc, o_dose)You can inspect the auto-generated intervals:
o_data$intervals |> head()# A tibble: 6 × 204
start end auclast aucall aumclast aumcall aucint.last aucint.last.dose
<dbl> <dbl> <lgl> <lgl> <lgl> <lgl> <lgl> <lgl>
1 0 24 TRUE FALSE FALSE FALSE FALSE FALSE
2 0 Inf FALSE FALSE FALSE FALSE FALSE FALSE
3 0 24 TRUE FALSE FALSE FALSE FALSE FALSE
4 0 Inf FALSE FALSE FALSE FALSE FALSE FALSE
5 0 24 TRUE FALSE FALSE FALSE FALSE FALSE
6 0 Inf FALSE FALSE FALSE FALSE FALSE FALSE
# ℹ 196 more variables: aucint.all <lgl>, aucint.all.dose <lgl>,
# aumcint.last <lgl>, aumcint.last.dose <lgl>, aumcint.all <lgl>,
# aumcint.all.dose <lgl>, c0 <lgl>, cmax <lgl>, cmin <lgl>, tmax <lgl>,
# tmin <lgl>, tlast <lgl>, tfirst <lgl>, clast.obs <lgl>, cl.last <lgl>,
# cl.all <lgl>, cl.int.all <lgl>, cl.int.last <lgl>, f <lgl>, mrt.last <lgl>,
# mrt.all <lgl>, mrt.int.all <lgl>, mrt.int.last <lgl>, mrt.iv.last <lgl>,
# vss.last <lgl>, vss.iv.last <lgl>, vss.all <lgl>, vss.int.all <lgl>, …2.2.5 Step 5 — pk.nca
Run all calculations:
o_nca <- pk.nca(o_data)2.2.6 Results
# Tidy data frame of all computed parameters
as.data.frame(o_nca) |> head(20)# A tibble: 20 × 6
Subject start end PPTESTCD PPORRES exclude
<ord> <dbl> <dbl> <chr> <dbl> <chr>
1 1 0 24 auclast 92.4 <NA>
2 1 0 Inf cmax 10.5 <NA>
3 1 0 Inf tmax 1.12 <NA>
4 1 0 Inf tlast 24.4 <NA>
5 1 0 Inf clast.obs 3.28 <NA>
6 1 0 Inf lambda.z 0.0485 <NA>
7 1 0 Inf r.squared 1.000 <NA>
8 1 0 Inf adj.r.squared 1.000 <NA>
9 1 0 Inf lambda.z.corrxy -1.000 <NA>
10 1 0 Inf lambda.z.time.first 9.05 <NA>
11 1 0 Inf lambda.z.time.last 24.4 <NA>
12 1 0 Inf lambda.z.n.points 3 <NA>
13 1 0 Inf clast.pred 3.28 <NA>
14 1 0 Inf half.life 14.3 <NA>
15 1 0 Inf span.ratio 1.07 <NA>
16 1 0 Inf aucinf.obs 215. <NA>
17 2 0 24 auclast 67.2 <NA>
18 2 0 Inf cmax 8.33 <NA>
19 2 0 Inf tmax 1.92 <NA>
20 2 0 Inf tlast 24.3 <NA> # Summary table (geometric mean ± CV% by default for most parameters)
summary(o_nca) start end N auclast cmax tmax half.life aucinf.obs
0 24 12 74.6 [24.3] . . . .
0 Inf 12 . 8.65 [17.0] 1.14 [0.630, 3.55] 8.18 [2.12] 115 [28.4]
Caption: auclast, cmax, aucinf.obs: geometric mean and geometric coefficient of variation; tmax: median and range; half.life: arithmetic mean and standard deviation; N: number of subjects2.3 Specifying intervals manually
Auto-interval detection works for simple designs. For complex studies (multiple doses, custom windows), define intervals yourself.
An interval is a row in a data frame with: - start, end: time boundaries - One column per parameter set to TRUE to request that parameter
# Request specific parameters over a specific window
my_intervals <- data.frame(
start = 0,
end = Inf,
auclast = TRUE,
aucinf.obs = TRUE,
cmax = TRUE,
tmax = TRUE,
half.life = TRUE
)
o_data2 <- PKNCAdata(o_conc, o_dose, intervals = my_intervals)
o_nca2 <- pk.nca(o_data2)
as.data.frame(o_nca2)# A tibble: 192 × 6
Subject start end PPTESTCD PPORRES exclude
<ord> <dbl> <dbl> <chr> <dbl> <chr>
1 6 0 Inf auclast 71.7 <NA>
2 6 0 Inf cmax 6.44 <NA>
3 6 0 Inf tmax 1.15 <NA>
4 6 0 Inf tlast 23.8 <NA>
5 6 0 Inf clast.obs 0.92 <NA>
6 6 0 Inf lambda.z 0.0878 <NA>
7 6 0 Inf r.squared 0.998 <NA>
8 6 0 Inf adj.r.squared 0.998 <NA>
9 6 0 Inf lambda.z.corrxy -0.999 <NA>
10 6 0 Inf lambda.z.time.first 2.03 <NA>
# ℹ 182 more rows2.4 Controlling calculations with PKNCA.options()
PKNCA.options() is the global settings registry. Call with no arguments to see all current settings.
PKNCA.options()$adj.r.squared.factor
[1] 1e-04
$max.missing
[1] 0.5
$auc.method
[1] "lin up/log down"
$conc.na
[1] "drop"
$conc.blq
$conc.blq$first
[1] "keep"
$conc.blq$middle
[1] "drop"
$conc.blq$last
[1] "keep"
$debug
NULL
$first.tmax
[1] TRUE
$first.tmin
[1] TRUE
$allow.tmax.in.half.life
[1] FALSE
$keep_interval_cols
NULL
$min.hl.points
[1] 3
$min.span.ratio
[1] 2
$max.aucinf.pext
[1] 20
$min.hl.r.squared
[1] 0.9
$progress
[1] TRUE
$tau.choices
[1] NA
$single.dose.aucs
start end auclast aucall aumclast aumcall aucint.last aucint.last.dose
1 0 24 TRUE FALSE FALSE FALSE FALSE FALSE
2 0 Inf FALSE FALSE FALSE FALSE FALSE FALSE
aucint.all aucint.all.dose aumcint.last aumcint.last.dose aumcint.all
1 FALSE FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE FALSE
aumcint.all.dose c0 cmax cmin tmax tmin tlast tfirst clast.obs cl.last
1 FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
2 FALSE FALSE TRUE FALSE TRUE FALSE FALSE FALSE FALSE FALSE
cl.all cl.int.all cl.int.last f mrt.last mrt.all mrt.int.all mrt.int.last
1 FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
mrt.iv.last vss.last vss.iv.last vss.all vss.int.all vss.int.last cav
1 FALSE FALSE FALSE FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE FALSE FALSE FALSE
cav.int.last cav.int.all ctrough cstart ptr tlag deg.fluc swing ceoi
1 FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
aucabove.predose.all aucabove.trough.all count_conc count_conc_measured
1 FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE
totdose volpk ae clr.last clr.obs clr.pred fe ertlst ermax ertmax
1 FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
sparse_auclast sparse_auc_se sparse_auc_df sparse_aumclast sparse_aumc_se
1 FALSE FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE FALSE
sparse_aumc_df time_above aucivlast aucivall aucivint.last aucivint.all
1 FALSE FALSE FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE FALSE FALSE
aucivpbextlast aucivpbextall aucivpbextint.last aucivpbextint.all aumcivlast
1 FALSE FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE FALSE
aumcivall aumcivint.last aumcivint.all half.life r.squared adj.r.squared
1 FALSE FALSE FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE TRUE FALSE FALSE
lambda.z.corrxy lambda.z lambda.z.time.first lambda.z.time.last
1 FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE
lambda.z.n.points clast.pred span.ratio tobit_residual adj_tobit_residual
1 FALSE FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE FALSE
lambda.z.n.points_blq thalf.eff.last thalf.eff.iv.last kel.last kel.iv.last
1 FALSE FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE FALSE
kel.all kel.int.all kel.int.last cl.iv.all cl.iv.last cl.ivint.all
1 FALSE FALSE FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE FALSE FALSE
cl.ivint.last cl.sparse.last mrt.sparse.last mrt.iv.all mrt.ivint.all
1 FALSE FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE FALSE
mrt.ivint.last vz.all vz.int.all vz.int.last vz.iv.all vz.iv.last
1 FALSE FALSE FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE FALSE FALSE
vz.ivint.all vz.ivint.last vz.last vss.iv.all vss.ivint.all vss.ivint.last
1 FALSE FALSE FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE FALSE FALSE
vss.sparse.last aucinf.obs aucinf.pred aumcinf.obs aumcinf.pred
1 FALSE FALSE FALSE FALSE FALSE
2 FALSE TRUE FALSE FALSE FALSE
aucint.inf.obs aucint.inf.obs.dose aucint.inf.pred aucint.inf.pred.dose
1 FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE
aumcint.inf.obs aumcint.inf.obs.dose aumcint.inf.pred aumcint.inf.pred.dose
1 FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE
aucivinf.obs aucivinf.pred aucivpbextinf.obs aucivpbextinf.pred aumcivinf.obs
1 FALSE FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE FALSE
aumcivinf.pred aucpext.obs aucpext.pred kel.iv.all kel.ivint.all
1 FALSE FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE FALSE
kel.ivint.last kel.sparse.last cl.obs cl.pred cl.int.inf.obs cl.int.inf.pred
1 FALSE FALSE FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE FALSE FALSE
cl.iv.obs cl.iv.pred mrt.obs mrt.pred mrt.int.inf.obs mrt.int.inf.pred
1 FALSE FALSE FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE FALSE FALSE
mrt.iv.obs mrt.iv.pred mrt.md.obs mrt.md.pred vz.obs vz.pred vz.int.inf.obs
1 FALSE FALSE FALSE FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE FALSE FALSE FALSE
vz.int.inf.pred vz.iv.obs vz.iv.pred vz.sparse.last vss.obs vss.pred
1 FALSE FALSE FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE FALSE FALSE
vss.iv.obs vss.iv.pred vss.md.obs vss.md.pred vss.int.inf.obs
1 FALSE FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE FALSE
vss.int.inf.pred cav.int.inf.obs cav.int.inf.pred thalf.eff.obs
1 FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE
thalf.eff.pred thalf.eff.iv.obs thalf.eff.iv.pred kel.obs kel.pred kel.iv.obs
1 FALSE FALSE FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE FALSE FALSE
kel.iv.pred kel.int.inf.obs kel.int.inf.pred auclast.dn aucall.dn
1 FALSE FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE FALSE
aucinf.obs.dn aucinf.pred.dn aumclast.dn aumcall.dn aumcinf.obs.dn
1 FALSE FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE FALSE
aumcinf.pred.dn cmax.dn cmin.dn clast.obs.dn clast.pred.dn cav.dn ctrough.dn
1 FALSE FALSE FALSE FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE FALSE FALSE FALSE
clr.last.dn clr.obs.dn clr.pred.dn
1 FALSE FALSE FALSE
2 FALSE FALSE FALSE
$allow_partial_missing_units
[1] FALSE
$hl_method
[1] "log-linear"
$tobit_n_points_penalty
[1] 0
$tobit_optim_control
list()All options and what they control:
AUC / integration
| Option | Default | Effect |
|---|---|---|
auc.method |
"lin up/log down" |
Integration rule: "linear", "lin-log", or "lin up/log down" |
Half-life / λz
| Option | Default | Effect |
|---|---|---|
min.hl.points |
3 |
Minimum data points for a valid λz regression |
min.hl.r.squared |
0.9 |
Minimum unadjusted R² for λz acceptance (post-hoc exclusion via exclude_nca_min.hl.r.squared()) |
adj.r.squared.factor |
0.0001 |
Selection tolerance: the longest regression window whose adj.R² is within this value of the best adj.R² is chosen (favours more points when fits are nearly equal) |
min.span.ratio |
2 |
Minimum ratio of time span to half-life; rejects regressions over too short a window |
allow.tmax.in.half.life |
FALSE |
Allow Tmax timepoint in λz regression |
hl_method |
"log-linear" |
"log-linear" (OLS) or "tobit" (censored-likelihood, ≥ 0.12.2) |
tobit_n_points_penalty |
0 |
Penalty per extra terminal point in Tobit log-likelihood; positive values favour shorter windows |
tobit_optim_control |
list() |
Control list forwarded to stats::optim() for Tobit optimisation |
AUCinf extrapolation
| Option | Default | Effect |
|---|---|---|
max.aucinf.pext |
20 |
Flag results where extrapolated % of AUCinf exceeds this threshold |
Concentration handling
| Option | Default | Effect |
|---|---|---|
conc.na |
"drop" |
NA concentrations: "drop" removes them; a number substitutes that value |
conc.blq |
list(first="keep", middle="drop", last="keep") |
BLQ concentrations: "drop", "keep", or a number globally; or a named list with keys first (before first non-BLQ), middle (between non-BLQs), last (after last non-BLQ), or before.tmax/after.tmax |
Tmax / Tmin
| Option | Default | Effect |
|---|---|---|
first.tmax |
TRUE |
TRUE = return first Tmax when tied; FALSE = return last |
first.tmin |
TRUE |
TRUE = return first Tmin when tied; FALSE = return last |
Summary / output
| Option | Default | Effect |
|---|---|---|
max.missing |
0.5 |
Maximum fraction of missing values allowed before suppressing a summary statistic |
keep_interval_cols |
NULL |
Additional columns from the intervals data frame to carry through to results |
allow_partial_missing_units |
FALSE |
Allow some parameters to lack unit definitions when a units table is provided |
single.dose.aucs |
(list) | Default interval specifications used when no intervals are provided for a single dose |
tau.choices |
NA |
Candidate dosing intervals (τ) for auto-detection in multiple-dose designs |
progress |
TRUE |
Show progress bar during pk.nca() |
debug |
NULL |
Enable internal debug output (not for routine use) |
Override for a single analysis by passing options to PKNCAdata():
o_data_strict <- PKNCAdata(
o_conc, o_dose,
options = list(
min.hl.points = 4, # require at least 4 points for half-life
min.hl.r.squared = 0.95 # stricter R² threshold
)
)2.5 Extracting and plotting results
results_df <- as.data.frame(o_nca)
# Filter to one parameter
auclast_df <- results_df |>
filter(PPTESTCD == "auclast")
ggplot(auclast_df, aes(x = Subject, y = PPORRES)) +
geom_col(fill = "steelblue") +
labs(title = "AUClast by Subject", x = "Subject", y = "AUClast (h·mg/L)") +
theme_minimal()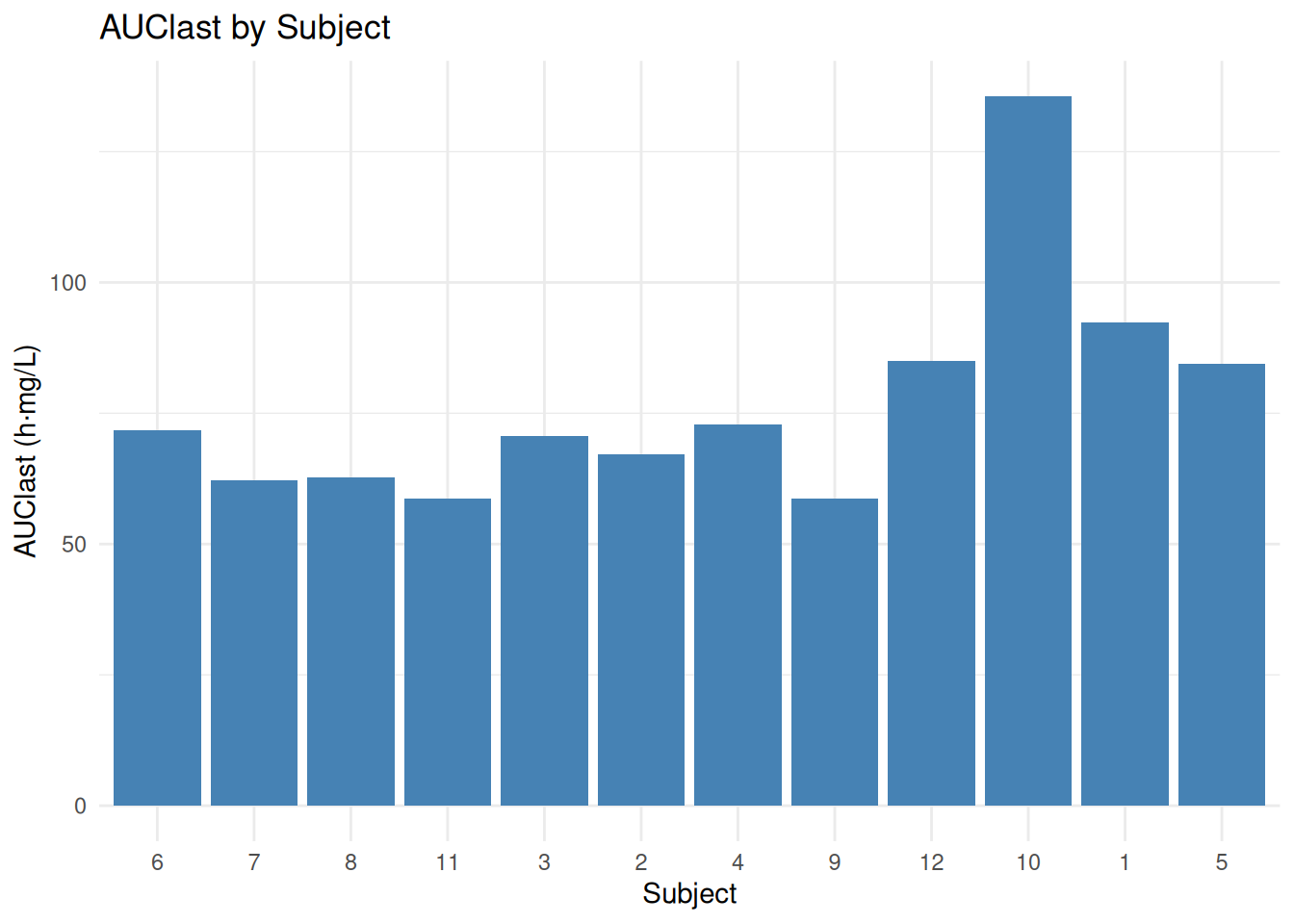
2.6 Re-running with different options
PKNCA does not have an update() method. To rerun with changed settings, pass a new options list to PKNCAdata() and call pk.nca() again:
# Change AUC method and recalculate
o_data_linear <- PKNCAdata(o_conc, o_dose, options = list(auc.method = "linear"))
o_nca_linear <- pk.nca(o_data_linear)